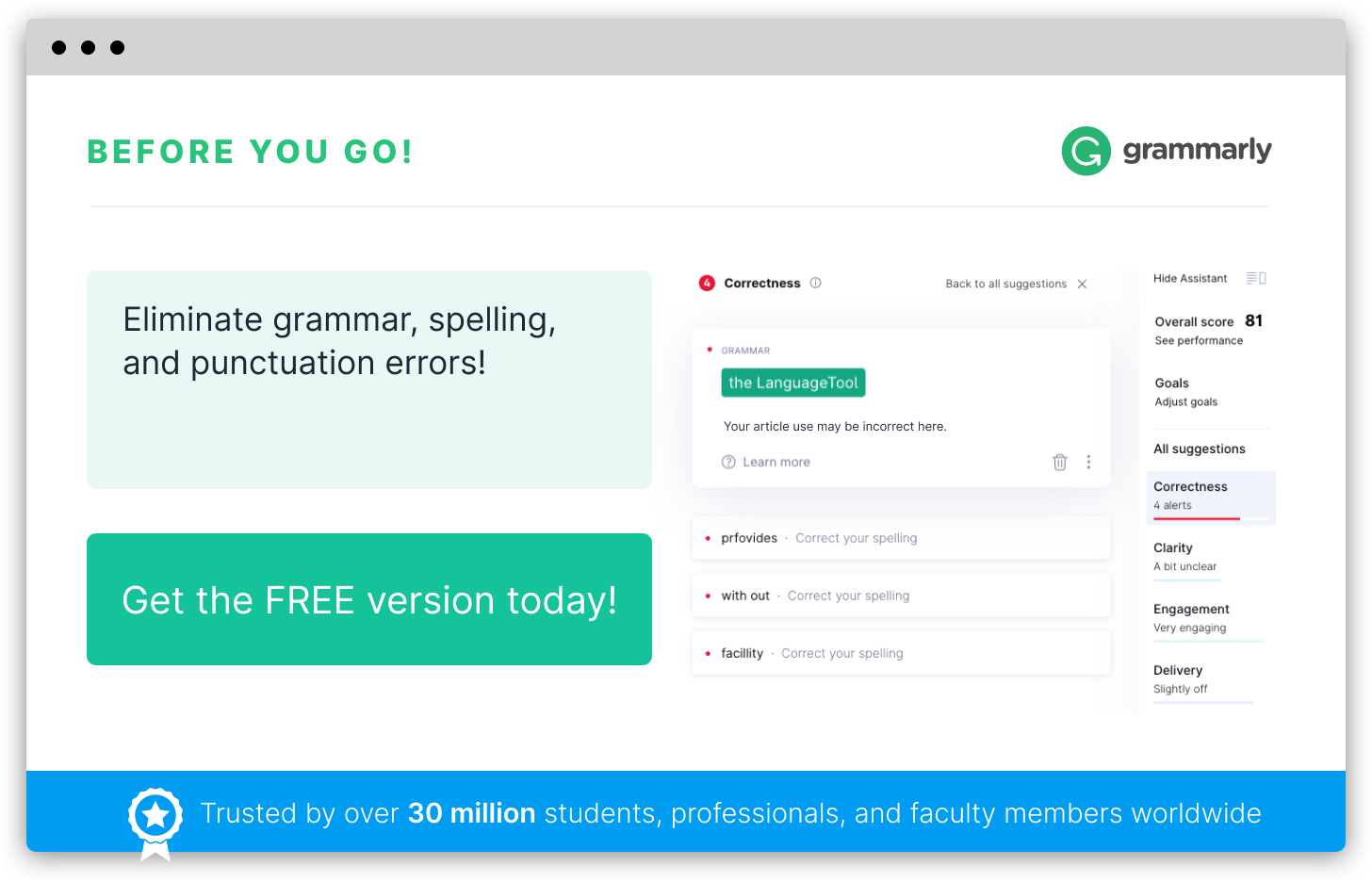
When used to refer to language and dictionaries, corpus (“corpus linguistics”) is an extensive collection of written or audio samples (“corpora”) used in the study of language.
Early attempts to study language in this way were based on cultural and religious texts, such as Sanskrit, Hebrew and Arabic writings. Once gathered by hand, these collections are now automated and are organized in electronic databases; many online databases exist that use the internet as their main source for samples.
The corpus shows how a language is evolving according to trends such as frequency of word use, changes in spelling, the emergence of new words and so forth. Those who collect data believe the best samples are gathered in the field with as little experimental interference as possible. They feel the text should “speak for itself” and tend to include very few notes with each sample.
The largest dictionary companies have enormous collections which they monitor carefully and continually. As words and the language change, they will adjust their yearly dictionary to reflect this linguistic evolution. One of the largest corpora has 2.5 billion words in 21st century English, with new samples continuously collected. Available through the internet is the 400 million word “Corpus of Contemporary American English”; begun in 1990, it is constantly maintained and updated.